
Expanding the CareerNet Benchmark: A Frontier Model Update
CareerNet was built to measure how well AI models deliver career guidance. This update extends the benchmark pilot to include one additional model: Anthropic's Claude Fable, a frontier system built for complex, long-context reasoning tasks.
Background: CareerNet
CareerNet is a dataset that covers three high-growth career domains: allied health, computer science, and reskilling pathways. The datasets draw from CareerVillage, an online community that has crowdsourced thousands of career-related questions across a wide range of occupations and learner needs. Each dataset was reviewed and rated by career navigation experts for completeness, coherence, and correctness, and includes metadata labels to help AI systems better understand user intent.
As a pilot study, our initial benchmarking sampled 300 questions and evaluated responses from three models - GPT-5.2, Gemini 2.5 Flash, and Llama 4 Maverick - across those same two dimensions. Results were promising but mixed: LLMs generally outperformed human responses, though 23–30% still fell short of the top completeness score. The full findings are available here.
What We Found
On both dimensions we measure - coherence and completeness - Claude Fable outperformed every other model in the benchmark, including the three models in our original study: OpenAI's GPT-5.2, Google's Gemini 2.5 Flash, and Meta's Llama 4 Maverick. That result comes with an important asterisk: Claude Fable costs roughly 33 times more per input token than Gemini 2.5 Flash, and 20 times more per output token. At that price, it is not a realistic option for platforms delivering career guidance at scale.
On coherence - how well-structured and logically organized a response is - Claude Fable ranked first, translating to roughly a 70% probability of producing a more coherent response than the weakest-performing LLM in the benchmark.
Figure 1. Coherency: Raw Win Rate
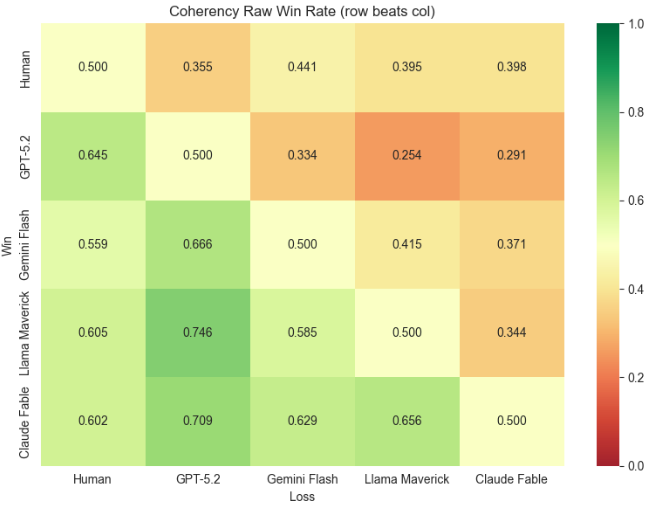
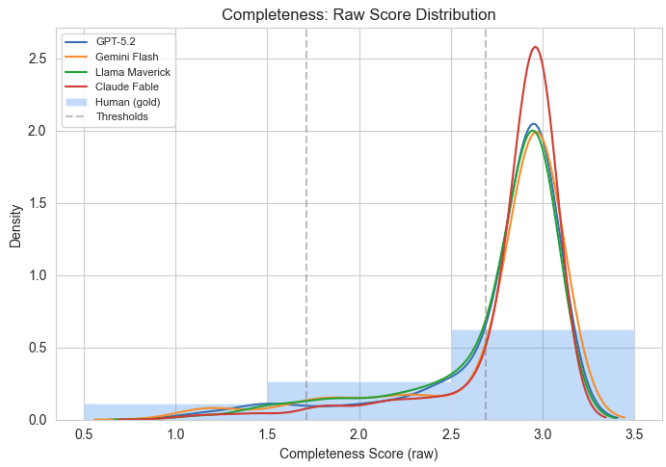
On completeness - how thoroughly a response addresses the question - it again led the field, with 84% of responses receiving the top score, compared to 74–79% for the other LLMs tested. Human responses from CareerVillage trailed all LLMs on completeness, though on coherence they outperformed GPT-5.2.
Figure 2. Completeness: Raw Score Distribution
One exception is worth noting: Claude Fable declined to answer one question in the dataset - an industry-specific knowledge item touching on biology rather than career navigation proper. This is consistent with broader reports of the model applying conservative content guardrails, and is worth flagging for developers whose pipelines may surface questions at the edges of career relevance.
What This Means
Claude Fable's performance confirms that frontier models with greater capacity can push the ceiling on coherence and completeness in career guidance tasks. It also sharpens a tension that CareerNet is well-positioned to track: the models that score best are often the least practical to deploy. For teams building real-world tools, the more cost-efficient models in the original benchmark remain the more relevant reference point.
This extension uses the same pipeline and carries the same limitations as the original study. Additionally, the completeness scoring model was retrained after the original was inadvertently removed; it used identical parameters and produced the same overall rankings, though exact scores may differ marginally. Taken together, these results are best read as a capacity test - a signal of what frontier models can do, not a guide to what teams should deploy.